Sunday, December 28, 2025
In modern sports, accessing data is easier than ever. With just a few clicks, you can reach a wide array of vital sports metrics such as attacking efficiency, Expected Goals (xG), and more. However, to avoid falling into the trap of misconceptions and to maintain objectivity when analyzing a match, you must clearly understand Data Bias and Sample Size.
In sports data analysis, the concept of Data Bias is frequently mentioned. You can understand Data Bias as “data deviation.” This occurs when the collected statistical data regarding a match does not accurately reflect the true ability or strength of a team or player. This leads analysts to form biased judgments and skewed conclusions.

What is Data Bias in sports analytics?
In sports, data bias occurs naturally and can emerge at any stage. This is because the conditions for collecting, recording, and interpreting match data are rarely perfect. Generally, there are three common types of data bias:
One of the most prevalent forms of data bias is Selection Bias. This occurs when an analyst cherry-picks data that aligns with their initial subjective assumptions while failing to consider the complete dataset of a match.
Specifically, analysts often focus on statistics concerning starting players, marquee stars, or players with standout moments. Meanwhile, they tend to overlook substitutes or those with limited playing time. Consequently, the gathered data fails to provide an accurate assessment of the team’s true collective strength.
Example: Suppose a player scores two goals in a single match. This statistic only reflects that specific player’s clinical finishing and form for that particular game. If you rely solely on this one performance to conclude that the player has a high scoring efficiency for the entire season, your judgment will be significantly skewed.
Context Bias is another frequent form of data deviation, as sports are always heavily influenced by the surrounding circumstances. Specifically:

Contextual bias occurs when ignoring contextual factors during data analysis.
Consequently, if sports data analysis overlooks these factors, it leads to significant bias. The match analysis will lack accuracy.
Example: A top-tier team facing a series of bottom-table opponents might secure consecutive victories with a high goal count. In this case, the statistical data becomes “inflated,” leading many to misjudge the team’s true strength. To form a correct assessment, statistics must be comprehensive and adjusted for the Strength of Schedule.
Survivorship Bias occurs when an analyst only focuses on the “survivors”—those who succeeded—while completely ignoring the cases that failed.
Example: When analyzing successful young players, many conclude that “starting a professional career early leads to success.” However, reality shows that thousands of young players followed that exact path but failed to make it. This indicates that previous data conclusions were flawed because they excluded “failed” cases from the analysis.
In sports data analysis, Sample Size refers to the number of observations or data points used to evaluate a player, a team, or a coach’s tactics. Specifically, Sample Size can include:

Sample size in sports analysis
Specifically, Sample Size can include metrics such as:
It is crucial to note that in statistics, the smaller the Sample Size, the lower the accuracy of the data analysis. This often leads to “inflated” metrics, which can result in misconceptions and incorrect conclusions.
Example: A player scores in two consecutive appearances. While this is a positive sign for the team, it does not necessarily mean the player is in “peak form.” With a Sample Size of only 2, the data is too limited to assess the player’s true capability. To reach a more accurate and objective judgment, you need to observe more matches, increasing the Sample Size to 4–5 games or more.
Sunwin has just revealed the essential insights regarding Data Bias & Sample Size. As you can see, both factors significantly influence the true meaning of sports statistics. Therefore, when analyzing sports data, always remember to evaluate carefully and place every number within its real-world context to minimize errors and biases.

Sharp Money and Public Money are two concepts frequently encountered in sports betting. However, not every player fully understands the essence of these terms or why they are so vital to the betting experience. In this article, Sunwin will answer all your questions in detail, helping you grasp these concepts to achieve the best possible betting results. 1. Properly Understanding Sharp Money vs. Public Money Simply put, Sharp Money and...
In the world of sports betting, Implied Probability and Margin are two terms you must master. These concepts are the keys to making smart investment decisions and avoiding unnecessary risks. Let’s dive into the details below. 1. What is Implied Probability? Simply put, Implied Probability is the “hidden likelihood” within a bet. It is the process of converting betting odds into a percentage that represents the bookmaker’s assessment of an...
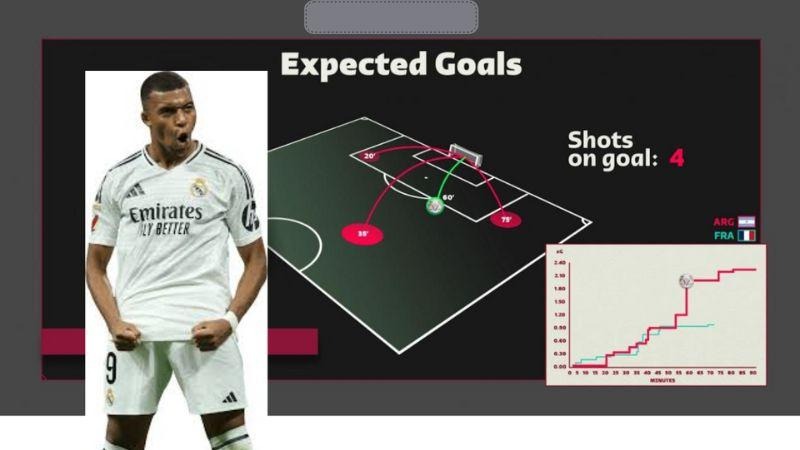
In modern football, experts, coaches, and fans use numerous metrics to dissect a match. One of the most prominent is Expected Goals (xG). So, what exactly is Expected Goals? How is it calculated, and what role does it play? Let’s dive into this in-depth analysis to gain a more accurate perspective when analyzing football data. 1. What is Expected Goals (xG)? Expected Goals, commonly abbreviated as xG, is a key...


